
Microsoft’s New Maia 200 Chip Steps Up to Make AI Responses Cheaper and Faster


Microsoft has recently launched its latest custom AI processor, the Maia 200, and the timing, or should I say circumstances, of its release could not be more coincidental. Inference, the stage where a trained AI model generates responses and other outputs, has become the most expensive part of running AI systems at scale. To address that issue square on, Microsoft designed the Maia 200 from the ground up with the sole purpose of making inference more efficient and cost-effective, and the results are very evident.
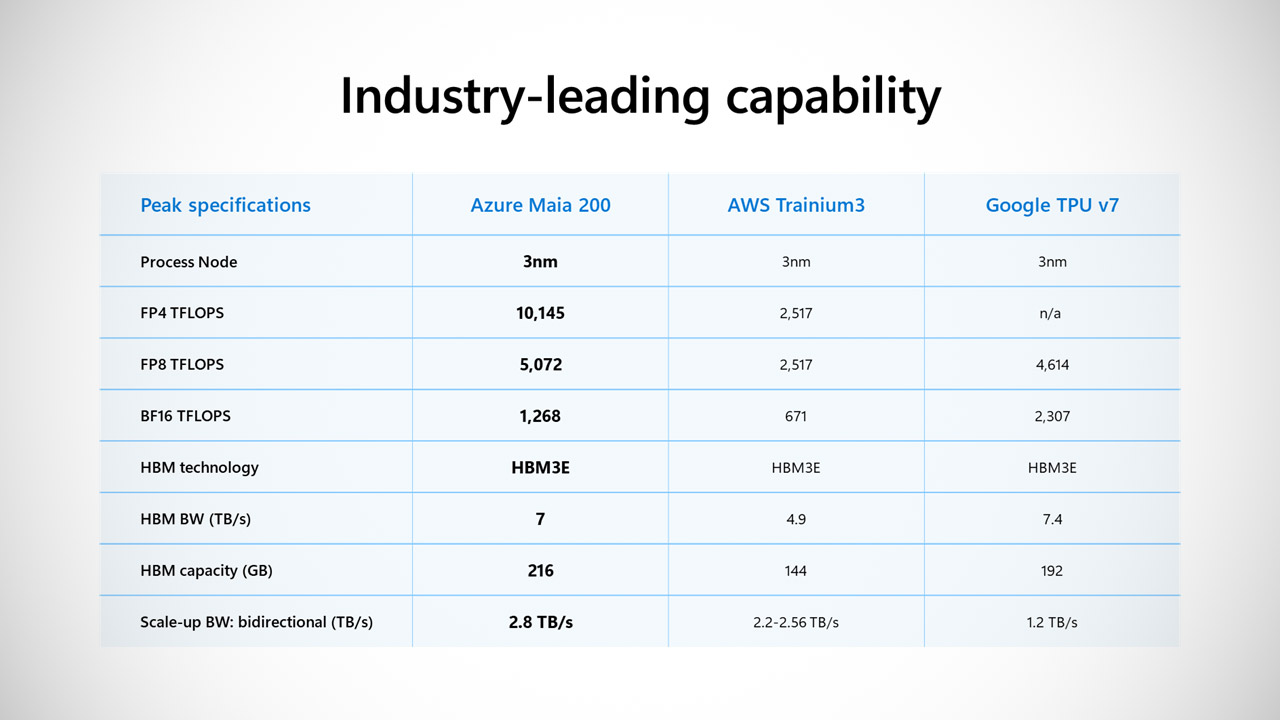
The Maia 200 chip was designed using TSMC’s 3nm process node, resulting in a tiny chip with an amazing 140 billion transistors. Each one provides a scorching 10 petaFLOPS of computing in FP4 accuracy and a still-not-slow 5 petaFLOPS in FP8. Memory is also no slacker, with 216GB of HBM3e running at 7 TB/s bandwidth and 272MB of on-chip SRAM neatly organized in a multitier hierarchy. What about the power draw? The TDP for the entire system-on-chip package is not minor, at 750W. Those stats are undoubtedly making the rivals look a little green around the gills.

ASUS ROG Xbox Ally – 7” 1080p 120Hz Touchscreen Gaming Handheld, 3-month Xbox Game Pass Premium…
- XBOX EXPERIENCE BROUGHT TO LIFE BY ROG The Xbox gaming legacy meets ROG’s decades of premium hardware design in the ROG Xbox Ally. Boot straight into…
- XBOX GAME BAR INTEGRATION Launch Game Bar with a tap of the Xbox button or play your favorite titles natively from platforms like Xbox Game Pass,…
- ALL YOUR GAMES, ALL YOUR PROGRESS Powered by Windows 11, the ROG Xbox Ally gives you access to your full library of PC games from Xbox and other game…
Microsoft is making the Maia 200 look like a monster by comparing it to the competition. For starters, it has three times the FP4 performance of Amazon’s third-generation Trainium processor, and its FP8 performance rivals Google’s seventh-generation TPU. It’s more than delighted to report that a single node can handle the largest models we have today while still leaving opportunity for ever larger and better models in the future. They also promise 30% greater performance per dollar than the Maia 100, which saw some real-world application.

The chip has already been deployed in Azure’s US Central area near Des Moines, Iowa, with US West 3 near Phoenix, Arizona, set to follow shortly. It’s more than just a shiny new processor; it’s already supporting real workloads for Microsoft’s Superintelligence team, such as synthetic data generation and reinforcement learning, and it powers the Copilot features we all know and love, as well as OpenAI models like GPT-5.2. And if you’re a developer or scholar looking for anything like this, you’re in luck: a preview SDK is available that interacts with PyTorch and contains a Triton compiler, an optimized kernel library, and a low-level language for fine-tuning models across diverse hardware.
Scott Guthrie, Microsoft’s head of cloud and AI, is pleased with the Maia 200, calling it the most efficient inference system the business has ever produced. The emphasis remains on lowering the real-world cost of producing AI tokens at scale. To be honest, every big cloud provider is under the same pressure: Nvidia’s GPUs have long been the go-to for much of the heavy lifting, but supply and pricing are catching up, forcing everyone to try something different. Microsoft is following Amazon and Google in this change, and the Maia 200 is essentially a chip that has gone all-in on inference rather than attempting to be a jack-of-all-trades.
Microsoft’s New Maia 200 Chip Steps Up to Make AI Responses Cheaper and Faster
#Microsofts #Maia #Chip #Steps #Responses #Cheaper #Faster







